

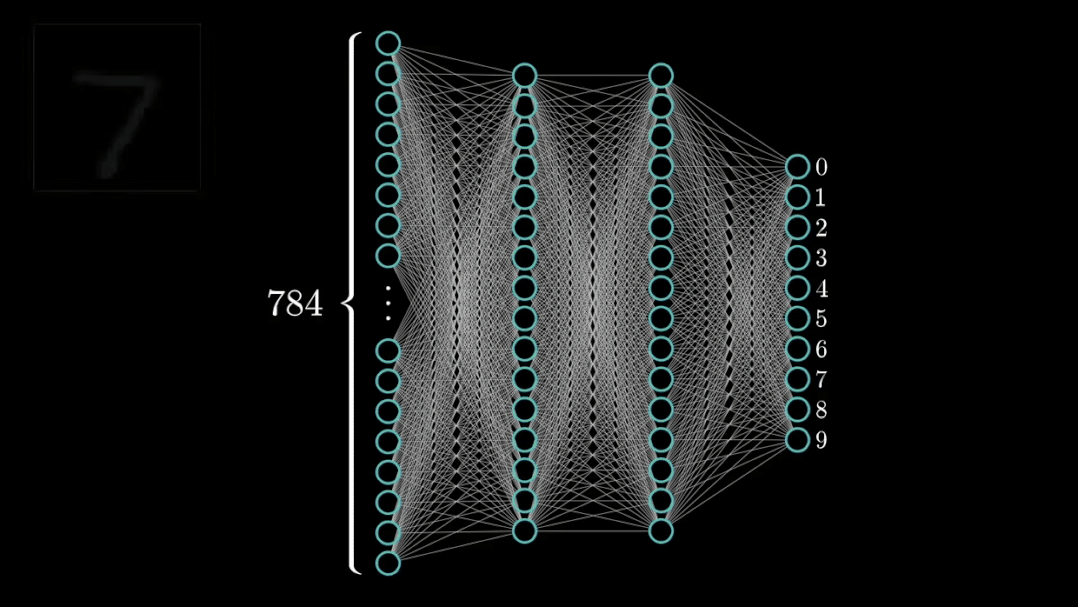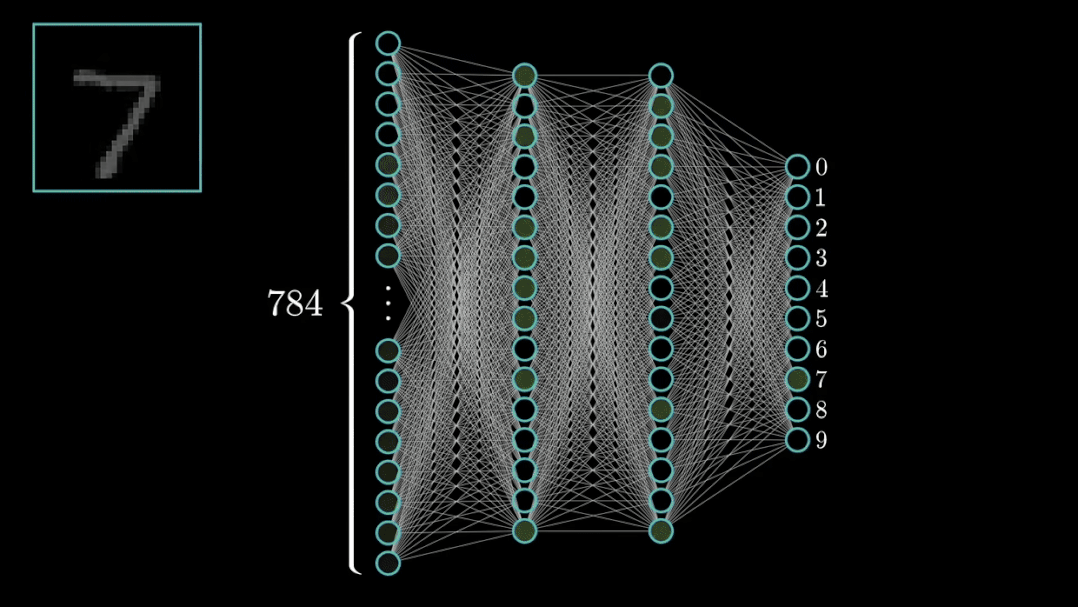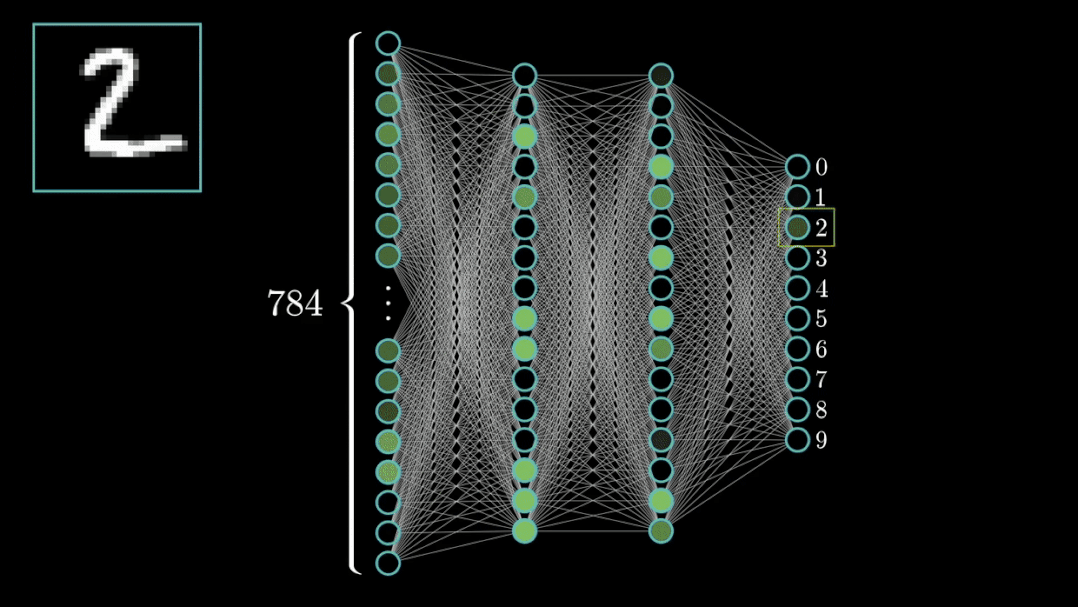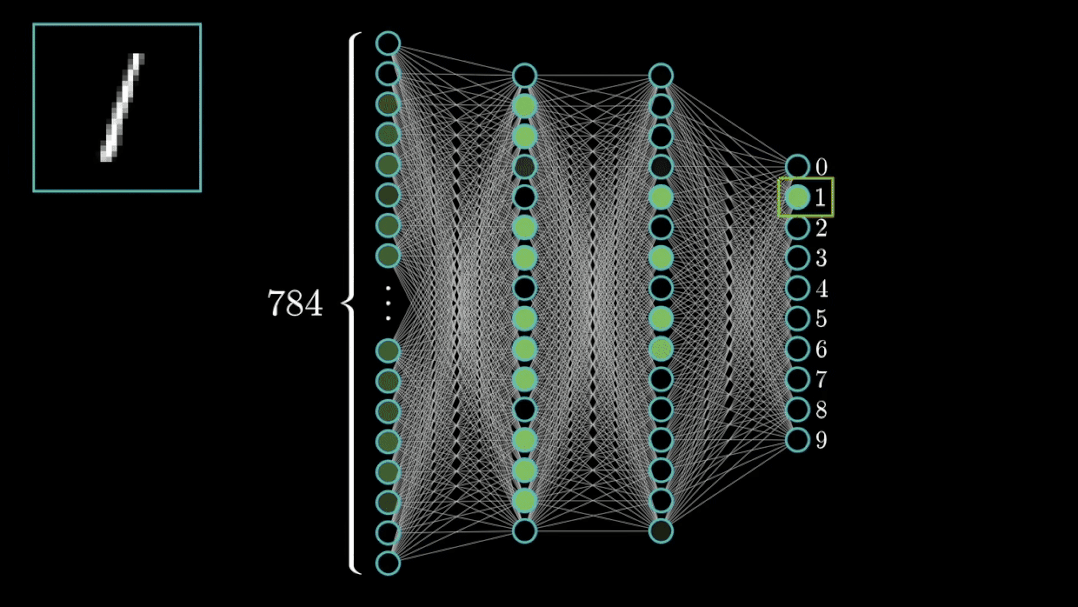
导包
不得不提, PyTorch 是目前深度学习领域非常火的框架之一。今天我以 MNIST 数据集 分类 为任务,为大家演示 PyTorch 的基本使用;并且,文末为大家提 供粘贴可运行 的代码。 如有错误,还请指正。 在开始之前,首先需要介绍 PyTorch 在计算机视觉领域中最重要的两个包: torch 与 torchvision:
torch 是 PyTorch 的核心库,提供了张量计算、自动微分等功能。
torchvision 是 PyTorch 的一个独立子库,主要用于计算机视觉任务,包括图像处理、数据加载、数据增强、预训练模型等。
import torch # pytorch 1.13.0+ 版本
from torch import nn, optim # 包含神经网络模块和优化器模块from torch.utils.data import DataLoader # DataLoader是PyTorch中用于加载数据的工具,可以自动处理批次、打乱数据等
import torchvision # torchvision是PyTorch的一个子库,包含了常用的数据集、模型和图像处理工具
from torchvision import datasets, transforms, models # datasets包含了常用的数据集,transforms包含了图像处理的变换函数,models包含了预训练模型和常用的网络结构目前来看,采用深度学习解决任何一个任务往往都需要这几个步骤:定义模型、训练模型、测试模型。
一、模型定义
针对 MNIST 数据集的分类任务,可采用经典的 AlexNet 模型,并使用 PyTorch 带有的预训练模型参数,初始化模型。
AlexNet 原始模型架构
AlexNet( (features): Sequential( (0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2)) (1): ReLU(inplace=True) (2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) (4): ReLU(inplace=True) (5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (7): ReLU(inplace=True) (8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (9): ReLU(inplace=True) (10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) ) (avgpool): AdaptiveAvgPool2d(output_size=(6, 6)) (classifier): Sequential( (0): Dropout(p=0.5, inplace=False) (1): Linear(in_features=9216, out_features=4096, bias=True) (2): ReLU(inplace=True) (3): Dropout(p=0.5, inplace=False) (4): Linear(in_features=4096, out_features=4096, bias=True) (5): ReLU(inplace=True) (6): Linear(in_features=4096, out_features=1000, bias=True) ))自定义神经网络模型
# 自定义神经网络模型类,继承自torch.nn.Module
class MyAlexNet(nn.Module):
def __init__(self, class_num):
super().__init__()
# 使用torchvision 0.13+ 推荐方式加载预训练模型权重,不再用 pretrained=True
weights = models.AlexNet_Weights.DEFAULT
self.net = models.alexnet(weights=weights)
# 修改AlexNet模型的分类器,调整输出类别数
# 这里AlexNet最后Flatten后的特征维度是256*6*6
self.net.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, class_num),
)
# 定义模型的前向传播函数 def forward(self, inputs):
return self.net(inputs)改完后的 AlexNet 模型结构 (示例: 要得到 10 分类的 AlexNet 模型对象)
alexnet = MyAlexNet(class_num=10) # 10 类分类任务
print(alexnet)
MyAlexNet( (net): AlexNet( (features): Sequential( (0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2)) (1): ReLU(inplace=True) (2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) (4): ReLU(inplace=True) (5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (7): ReLU(inplace=True) (8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (9): ReLU(inplace=True) (10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) ) (avgpool): AdaptiveAvgPool2d(output_size=(6, 6))
## 以下发生了修改
(classifier): Sequential( (0): Dropout(p=0.5, inplace=False) (1): Linear(in_features=9216, out_features=4096, bias=True) (2): ReLU(inplace=True) (3): Dropout(p=0.5, inplace=False) (4): Linear(in_features=4096, out_features=4096, bias=True) (5): ReLU(inplace=True) (6): Linear(in_features=4096, out_features=10, bias=True) ) ))二、定义训练函数
数据增强&数据集&数据加载器
数据增强,即 transform,一方面用于增加训练的数据量,提高模型的泛化能力,提升模型的鲁棒性;另一方面用于对样本进行处理,使其符合模型的输入。
transform = transforms.Compose([
transforms.Resize((96, 96)),
transforms.Grayscale(num_output_channels=3),
transforms.ToTensor(),
transforms.Normalize((0.2, 0.2, 0.2), (0.3, 0.3, 0.3))
])数据集,即 dataset,主要分为训练集与测试集。PyTorch 自带有 MNIST 数据集;该数据集是一个手写体数字的图片数据集,该图片为 28×2828×2828×2828×28 单通道黑白图片,训练集一共包含了 60,000 张样本,测试集一共包含了 10,000 张样本。
train_set = datasets.MNIST(root='./dataset', train=True, download=True, transform=transform)
test_set = datasets.MNIST(root='./dataset', train=False, download=True, transform=transform)数据加载器,即 data loader,是 PyTorch 为了方便模型训练与数据集加载提供的工具类;data loader 会将数据集中样本根据 batch_size 分割成一个一个的 mini-batch,方便后序的训练与测试过程(目前的训练与测试采用的大都是 mini-batch 的方式)。
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True) # shuffle=True表示每个epoch开始时打乱数据顺序
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False) # shuffle=False表示测试集不需要打乱顺序loss 损失函数
分类任务,毫无疑问,使用交叉熵损失函数 。根据模型的输出与正确结果,计算损失,同时可以根据自动微分功能,实现由 loss 函数而始的梯度反向传播。不得不说,通常说的模型,往往指的是参数模型,并不包含梯度;反向传播,传播的是模型的梯度.
criterion = nn.CrossEntropyLoss() # 使用交叉熵损失函数,适用于多分类问题优化器及学习率
优化器,即 optimizer,实现模型参数的更新。主要利用反向传播而来的梯度,以及采用梯度下降的方式,实现参数的更新: θn=θn−1−g∗lrθn = θn−1−g∗lr .其中 θn−1 代指模型当前参数; g 代指参数的梯度; lr 代指学习率,往往与学模型学习过程快慢有关; θn 代指优化器进行参数更新后的模型参数。
# 使用AdamW优化器,学习率设置为1e-4(lr=0.0001)optimizer = optim.AdamW(model.parameters(), lr=1e-4)定义训练函数
训练 (有监督训练) 是指将训练集输入到算法模型中,根据模型输出与正确标签计算损失,并通过反向传播与梯度下降的方式,对模型参数不断优化,使模型能够识别、分析和预测各种情况。注:最终得到的是模型的 参数 。
# 训练模型函数# Parameters(参数介绍):
# - data_loader: DataLoader对象,提供训练数据
# - model: nn.Module对象,待训练的模型
# - optimizer: 优化器对象,用于更新模型参数
# - criterion: 损失函数对象,用于计算损失
# - device: torch.device对象,指定计算设备(CPU或GPU)
# - epoch: 当前训练的轮次
# - print_freq: 打印频率,用于控制日志输出
# Returns:
# - total_loss: 平均损失值
# - total_acc: 平均准确率
def train_model(data_loader: DataLoader, model: nn.Module, optimizer: optim.Optimizer, criterion: nn.Module, device: torch.device, epoch: int, print_freq: int):
model.train() # 设置模型为训练模式
model.to(device) # 将模型移动到指定设备
total_loss, total_acc = 0., 0. # 初始化总损失和总准确率
batch_num = len(data_loader) # 获取批次数量
for idx, (img, target) in enumerate(data_loader, 1): # 遍历数据加载器 / enumerate(data_loader, 1) 从1开始计数到DataLoader的长度
img, target = img.to(device), target.to(device)# 为了使用GPU加速,必须将数据和模型都放到同一设备上
optimizer.zero_grad() #PyTorch默认梯度是累积的,所以每次训练前需要手动清零
outputs = model(img) # 使用前面定义的模型 前向传播,计算模型输出
loss = criterion(outputs, target)
loss.backward()
optimizer.step() # 反向传播,计算梯度并更新模型参数
pred = outputs.argmax(dim=1) # 找到预测输出中概率(或分数)最大的类别索引 / dim=1 指按行找最大值索引,即对每个样本找到最高得分类别。
acc = pred.eq(target).float().mean() # 计算准确率,pred.eq(target)返回一个布尔张量,表示预测是否正确,然后转换为浮点数并求平均值
total_loss += loss.item() # item()将张量转换为Python数值
total_acc += acc.item()
if idx % print_freq == 0 or idx == batch_num: # 累计当前批次的损失和准确率数值,方便后面计算整个epoch的平均
print(f"Epoch:{epoch:03d} Batch:[{idx}/{batch_num}] Loss:{loss.item():f} Acc:{acc.item():f}") # 解释 f-string格式化输出当前批次的损失和准确率 # epoch:03d表示epoch是3位数,不足补0,Batch:[{idx}/{batch_num}]表示当前批次和总批次数,Loss:{loss.item():f}表示损失值保留4位小数,Acc:{acc.item():f}表示准确率保留4位小数
# 示例 Epoch:001 Batch:[16/118] Loss:0.2009 Acc:0.9531
return total_loss / batch_num, total_acc / batch_num定义模型函数
在模型训练过程中或者训练结束后,需要使用测试集对模型进行测试;并根据模型在测试集上的推理准确率,评判模型的优劣。
# 测试模型函数# Parameters(参数介绍):
# - data_loader: DataLoader对象,提供测试数据
# - model: nn.Module对象,待测试的模型
# - criterion: 损失函数对象,用于计算损失
# - device: torch.device对象,指定计算设备(CPU或GPU)
# Returns:
# - total_loss: 平均损失值
# - total_acc: 平均准确率
def test_model(data_loader: DataLoader, model: nn.Module, criterion: nn.Module, device: torch.device):
model.eval()
model.to(device) #这里的model是训练过的模型,eval()方法将模型设置为评估模式,这会影响某些层(如Dropout和BatchNorm)的行为,使其在测试时表现得更稳定。
total_loss, total_acc = 0., 0.
batch_num = len(data_loader)
with torch.no_grad(): # 在测试时不需要计算梯度,使用torch.no_grad()可以节省内存和计算资源
for idx, (img, target) in enumerate(data_loader, 1):
img, target = img.to(device), target.to(device)
outputs = model(img)
loss = criterion(outputs, target)
pred = outputs.argmax(dim=1)
acc = pred.eq(target).float().mean()
total_loss += loss.item()
total_acc += acc.item()
return total_loss / batch_num, total_acc / batch_num完整代码 (包含定义函数与主函数)
针对以上定义,总结逻辑代码,在 pytorch 环境下粘贴运行
import torch # pytorch 1.13.0+ 版本
from torch import nn, optim # 包含神经网络模块和优化器模块
from torch.utils.data import DataLoader # DataLoader是PyTorch中用于加载数据的工具,可以自动处理批次、打乱数据等
import torchvision # torchvision是PyTorch的一个子库,包含了常用的数据集、模型和图像处理工具
from torchvision import datasets, transforms, models # datasets包含了常用的数据集,transforms包含了图像处理的变换函数,models包含了预训练模型和常用的网络结构
# 自定义神经网络模型类,继承自torch.nn.Module
class MyAlexNet(nn.Module):
def __init__(self, class_num):
super().__init__()
# 使用torchvision 0.13+ 推荐方式加载预训练模型权重,不再用 pretrained=True
weights = models.AlexNet_Weights.DEFAULT
self.net = models.alexnet(weights=weights)
# 修改AlexNet模型的分类器,调整输出类别数
# 这里AlexNet最后Flatten后的特征维度是256*6*6
self.net.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, class_num),
)
def forward(self, inputs):
return self.net(inputs)
# 定义训练和测试函数
# 训练模型函数
# Parameters:
# - data_loader: DataLoader对象,提供训练数据
# - model: nn.Module对象,待训练的模型
# - optimizer: 优化器对象,用于更新模型参数
# - criterion: 损失函数对象,用于计算损失
# - device: torch.device对象,指定计算设备(CPU或GPU)
# - epoch: 当前训练的轮次
# - print_freq: 打印频率,用于控制日志输出
# Returns:
# - total_loss: 平均损失值
# - total_acc: 平均准确率
def train_model(data_loader: DataLoader, model: nn.Module, optimizer: optim.Optimizer, criterion: nn.Module, device: torch.device, epoch: int, print_freq: int):
model.train() # 设置模型为训练模式
model.to(device) # 将模型移动到指定设备
total_loss, total_acc = 0., 0. # 初始化总损失和总准确率
batch_num = len(data_loader) # 获取批次数量
for idx, (img, target) in enumerate(data_loader, 1): # 遍历数据加载器 / enumerate(data_loader, 1) 从1开始计数到DataLoader的长度
img, target = img.to(device), target.to(device)# 为了使用GPU加速,必须将数据和模型都放到同一设备上
optimizer.zero_grad() #PyTorch默认梯度是累积的,所以每次训练前需要手动清零
outputs = model(img) # 使用前面定义的模型 前向传播,计算模型输出
loss = criterion(outputs, target)
loss.backward()
optimizer.step() # 反向传播,计算梯度并更新模型参数
pred = outputs.argmax(dim=1) # 找到预测输出中概率(或分数)最大的类别索引 / dim=1 指按行找最大值索引,即对每个样本找到最高得分类别。
acc = pred.eq(target).float().mean() # 计算准确率,pred.eq(target)返回一个布尔张量,表示预测是否正确,然后转换为浮点数并求平均值
total_loss += loss.item() # item()将张量转换为Python数值
total_acc += acc.item()
if idx % print_freq == 0 or idx == batch_num: # 累计当前批次的损失和准确率数值,方便后面计算整个epoch的平均
print(f"Epoch:{epoch:03d} Batch:[{idx}/{batch_num}] Loss:{loss.item():f} Acc:{acc.item():f}") # 解释 f-string格式化输出当前批次的损失和准确率 # epoch:03d表示epoch是3位数,不足补0,Batch:[{idx}/{batch_num}]表示当前批次和总批次数,Loss:{loss.item():f}表示损失值保留4位小数,Acc:{acc.item():f}表示准确率保留4位小数
# 示例 Epoch:001 Batch:[16/118] Loss:0.2009 Acc:0.9531
return total_loss / batch_num, total_acc / batch_num
# 测试模型函数
# Parameters:
# - data_loader: DataLoader对象,提供测试数据
# - model: nn.Module对象,待测试的模型
# - criterion: 损失函数对象,用于计算损失
# - device: torch.device对象,指定计算设备(CPU或GPU)
# Returns:
# - total_loss: 平均损失值
# - total_acc: 平均准确率
def test_model(data_loader: DataLoader, model: nn.Module, criterion: nn.Module, device: torch.device):
model.eval()
model.to(device) #这里的model是训练过的模型,eval()方法将模型设置为评估模式,这会影响某些层(如Dropout和BatchNorm)的行为,使其在测试时表现得更稳定。
total_loss, total_acc = 0., 0.
batch_num = len(data_loader)
with torch.no_grad(): # 在测试时不需要计算梯度,使用torch.no_grad()可以节省内存和计算资源
for idx, (img, target) in enumerate(data_loader, 1):
img, target = img.to(device), target.to(device)
outputs = model(img)
loss = criterion(outputs, target)
pred = outputs.argmax(dim=1)
acc = pred.eq(target).float().mean()
total_loss += loss.item()
total_acc += acc.item()
return total_loss / batch_num, total_acc / batch_num
# 为了组织代码逻辑,通常会将主要执行流程放在一个main函数中,这样可以更清晰地看到程序的结构和执行顺序。
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 设置设备,优先使用GPU
print(f"Using device: {device}")
# 定义数据变换 在这为了符合AlexNet的输入要求,将MNIST数据集的图像大小调整为96x96,并转换为3通道(RGB)图像。
# MNIST数据集原始图像是28x28的灰度图像
# AlexNet要求输入图像为3通道(RGB),所以需要将灰度图像转换为3通道。
# 另外,AlexNet通常使用较大的输入图像尺寸(如224x224),但这里为了适应MNIST数据集的特性,使用96x96作为输入尺寸。
# 归一化参数根据AlexNet的预训练权重进行设置,通常使用均值(0.2, 0.2, 0.2)和标准差(0.3, 0.3, 0.3)进行归一化处理。
transform = transforms.Compose([
transforms.Resize((96, 96)),
transforms.Grayscale(num_output_channels=3),
transforms.ToTensor(),
transforms.Normalize((0.2, 0.2, 0.2), (0.3, 0.3, 0.3))
])
# 下载与加载数据集
train_set = datasets.MNIST(root='./dataset', train=True, download=True, transform=transform)
test_set = datasets.MNIST(root='./dataset', train=False, download=True, transform=transform)
batch_size = 512 # 设置批次大小 ,总批次就是数据集大小除以批次大小=此处为60000/512=117.1875,向上取整为118个批次
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True) # shuffle=True表示每个epoch开始时打乱数据顺序
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False) # shuffle=False表示测试集不需要打乱顺序
# 实例化模型,定义损失函数和优化器
class_num = 10
model = MyAlexNet(class_num)
criterion = nn.CrossEntropyLoss() # 使用交叉熵损失函数,适用于多分类问题
optimizer = optim.AdamW(model.parameters(), lr=1e-4) # 使用AdamW优化器,学习率设置为1e-4
# 学习率调度器,30个epoch学习率乘以0.1 是为了在训练过程中逐渐降低学习率,以便模型在训练后期能够更精细地调整参数。
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
epoch_num = 5
print_freq = 16 # 打印频率,控制日志输出的频率 / 每16个批次打印一次训练日志
# 训练和测试 循环
best_acc = 0.0
for epoch in range(1, epoch_num + 1): # 训练5个epoch
train_loss, train_acc = train_model(train_loader, model, optimizer, criterion, device, epoch, print_freq)
#期间输出Epoch:001 Batch:[16/118] Loss:0.2009 Acc:0.9531 …
test_loss, test_acc = test_model(test_loader, model, criterion, device)
print(f"Epoch {epoch} Summary: Train Loss={train_loss:f}, Train Acc={train_acc:f} | Test Loss={test_loss:f}, Test Acc={test_acc:f}")
#示例 Epoch 5 Summary: Train Loss=0.0118, Train Acc=0.9962 | Test Loss=0.0281, Test Acc=0.9930
scheduler.step() # 更新学习率 / step()方法会根据预设的调度策略更新优化器的学习率。
# 早停示意(可按需启用)/ 在训练过程中监控验证集的性能,如果连续若干个epoch验证集性能没有提升,则提前停止训练以避免过拟合。
# if test_acc > best_acc:
# best_acc = test_acc
# torch.save(model.state_dict(), "best_model.pth")
# else:
# print("Early stopping triggered.")
# break
# 保存最终训练好的模型参数
torch.save(model.state_dict(), "alexnet_weight.pth")
print("模型参数已保存到 alexnet_weight.pth")
if __name__ == "__main__": # 在Python中,if __name__ == "__main__": 是一个常见的结构,用于判断当前脚本是否是直接运行的,而不是被导入到其他脚本中。
main()
# 如果当前脚本是直接运行的,则执行main函数
# 这样可以避免在导入时执行不必要的代码,保持代码的模块化和可重用性。
# 这种结构使得脚本既可以作为独立程序运行,也可以作为模块被其他脚本导入而不执行main函数中的代码。
# 例如:python testmodel.py
# 直接运行时会执行main函数,加载数据集,训练模型等;
# 如果在其他脚本中导入这个模块,则不会执行main函数中的代码
# 这样可以避免在导入时执行不必要的代码,保持代码的模块化和可重用性。
# 例如:from testmodel import MyAlexNet
# 导入时不会执行main函数中的代码,只会导入MyAlexNet类
# 这样可以避免在导入时执行不必要的代码,保持代码的模块化和可重用性。输出结果参考
Using device: cudaEpoch:001 Batch:[16/118] Loss:0.2009 Acc:0.9531Epoch:001 Batch:[32/118] Loss:0.1344 Acc:0.9629Epoch:001 Batch:[48/118] Loss:0.0443 Acc:0.9844Epoch:001 Batch:[64/118] Loss:0.0312 Acc:0.9902Epoch:001 Batch:[80/118] Loss:0.0400 Acc:0.9883Epoch:001 Batch:[96/118] Loss:0.0484 Acc:0.9844Epoch:001 Batch:[112/118] Loss:0.0440 Acc:0.9844Epoch:001 Batch:[118/118] Loss:0.0805 Acc:0.9792Epoch 1 Summary: Train Loss=0.1539, Train Acc=0.9518 | Test Loss=0.0317, Test Acc=0.9901Epoch:002 Batch:[16/118] Loss:0.0433 Acc:0.9941Epoch:002 Batch:[32/118] Loss:0.0418 Acc:0.9883Epoch:002 Batch:[48/118] Loss:0.0536 Acc:0.9863Epoch:002 Batch:[64/118] Loss:0.0260 Acc:0.9902Epoch:002 Batch:[80/118] Loss:0.0493 Acc:0.9883Epoch:002 Batch:[96/118] Loss:0.0181 Acc:0.9922Epoch:002 Batch:[112/118] Loss:0.0154 Acc:0.9941Epoch:002 Batch:[118/118] Loss:0.0007 Acc:1.0000Epoch 2 Summary: Train Loss=0.0309, Train Acc=0.9904 | Test Loss=0.0303, Test Acc=0.9908Epoch:003 Batch:[16/118] Loss:0.0236 Acc:0.9902Epoch:003 Batch:[32/118] Loss:0.0037 Acc:1.0000Epoch:003 Batch:[48/118] Loss:0.0156 Acc:0.9961Epoch:003 Batch:[64/118] Loss:0.0355 Acc:0.9922Epoch:003 Batch:[80/118] Loss:0.0103 Acc:0.9961Epoch:003 Batch:[96/118] Loss:0.0101 Acc:0.9941Epoch:003 Batch:[112/118] Loss:0.0115 Acc:0.9980Epoch:003 Batch:[118/118] Loss:0.0718 Acc:0.9792Epoch 3 Summary: Train Loss=0.0205, Train Acc=0.9935 | Test Loss=0.0318, Test Acc=0.9902Epoch:004 Batch:[16/118] Loss:0.0140 Acc:0.9922Epoch:004 Batch:[32/118] Loss:0.0177 Acc:0.9941Epoch:004 Batch:[48/118] Loss:0.0142 Acc:0.9941Epoch:004 Batch:[64/118] Loss:0.0179 Acc:0.9922Epoch:004 Batch:[80/118] Loss:0.0100 Acc:0.9961Epoch:004 Batch:[96/118] Loss:0.0267 Acc:0.9883Epoch:004 Batch:[112/118] Loss:0.0163 Acc:0.9922Epoch:004 Batch:[118/118] Loss:0.0180 Acc:0.9896Epoch 4 Summary: Train Loss=0.0149, Train Acc=0.9953 | Test Loss=0.0360, Test Acc=0.9910Epoch:005 Batch:[16/118] Loss:0.0023 Acc:1.0000Epoch:005 Batch:[32/118] Loss:0.0043 Acc:1.0000Epoch:005 Batch:[48/118] Loss:0.0191 Acc:0.9961Epoch:005 Batch:[64/118] Loss:0.0038 Acc:1.0000Epoch:005 Batch:[80/118] Loss:0.0413 Acc:0.9922Epoch:005 Batch:[96/118] Loss:0.0060 Acc:0.9980Epoch:005 Batch:[112/118] Loss:0.0103 Acc:0.9980Epoch:005 Batch:[118/118] Loss:0.0555 Acc:0.9792Epoch 5 Summary: Train Loss=0.0118, Train Acc=0.9962 | Test Loss=0.0281, Test Acc=0.9930模型参数已保存到 alexnet_weight.pth